

















经验分享 | 先楫 HPM片上 Cache使用指南


贾 工
先楫资深FAE工程师
12年产品研发经验,具有变频器、伺服等工业产品开发经验,也负责过激光投影显示系统开发、AI应用开发、PYQT、Linux驱动开发等工作。
概 述
高速缓存(Cache)主要是为了解决CPU运算速度与内存(Memory)读写速度不匹配的矛盾而存在, 是CPU与存储设备之间的临时存贮器,容量小,但是交换速度比内存快。内置高速缓存通常对CPU的性能提升具有较大作用。
CPU要读取一个数据时,首先从Cache中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入Cache中,可以使得以后对整块数据的读取都从Cache中进行,不必再调用内存。
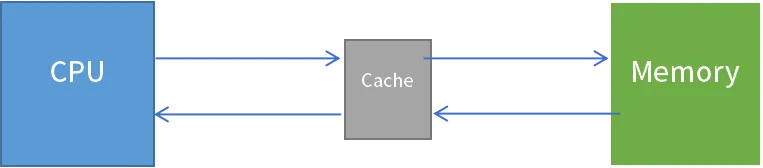
这样的读取机制使CPU读取Cache的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在Cache中,只有大约10%需要从内存读取。HPM CPU访问片上的Cache内数据是零等待的,这大大节省了CPU直接读取内存数据的时间,使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先Cache后存储设备。
一、Cacheable Memory 相关概念
在访问HPM片上ILM与DLM(Local Memory)时,芯片物理结构决定了CPU不会使用Cache去缓存Local Memory的数据。访问其它存储设备如flash、sram、sdram等,则Cache可以发挥其缓存机制来加快访问速度。在Cache生效的地址空间内,用户可以设置Memory的物理存储属性来设置是否对指定的地址空间使用Cache。
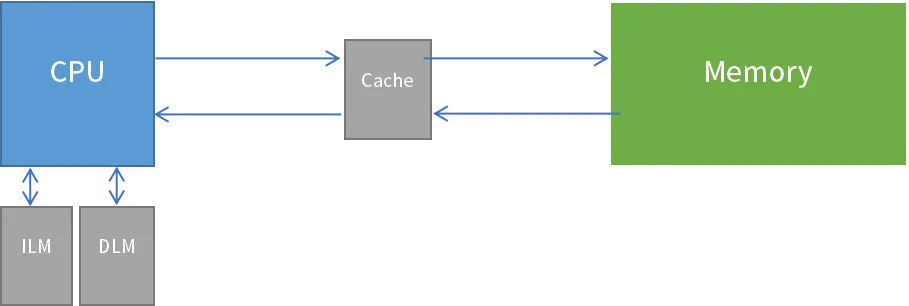
PMA(Physical Memory Attributes)是指一段存储地址空间的可读写、可执行、可缓存等属性。读、写、执行等属性容易理解,此处不赘述。下面介绍几个其它属性及相关的概念。(注意:HPM5300系列不支持PMA设置)
首先介绍一些Cache基本概念。
1. Cache Line/dirty/invalidate
Cache Line:一次最少缓存多少字节的数据是有要求的,通常以Cache Line为单位。HPM6000系列MCU Cache Line为64byte,HPM5300系列MCU Cache Line为32byte。在进行PMA设置时,要求起始地址按Cache Line字节数对齐,大小为Cache Line大小的整数倍。声明数组时最好也遵循此规则。
Dirty:表示某Cache Line的数据是否与Memory保持一致,如果只将数据写入Cache而没有写入Memory,会将该Cache Line标记为dirty。
Invalidate:将某地址范围的Cache Line数据失效掉,当Cache Line状态被Invalidate时,不管读取是否命中,CPU都会到Memory拿数据。
对Cache的标准操作包括 write-back,invalidate,flush。
Write-back表示把cache内dirty的数据写入Memory,invalidate表示忽略某地址范围的Cache line,flush操作则先对某Cache Line 进行write-back操作,再进行invalidate操作。HPM SDK的hpm_l1c_drv.h文件提供了这3种操作的接口函数。
2. Bufferable
Bufferable是指MCU在写入一片内存区时,是否可使用Write buffer进行加速。例如向sram内写入64个字节:
1)不使用Bufferable:CPU等待64字节数据写入完成后再去执行其它指令;
2)使用Bufferable:CPU将64字节数据写入Write buffer,不等Write buffer内的数据写入sram,CPU就去执行其它指令;写入动作则自动进行直至完成。
3. Cacheable
Cacheable与 non-Cacheable,决定了CPU是否启用缓存特性。如果启用Cacheable特性,则HPM芯片上的内存区域可以分区指定PMA,可选的属性选项如下(详细信息可参考先楫官方文档HPM6200 UM 2.8章节):
Write-Back
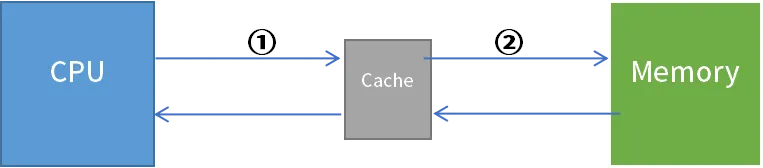
Write-Back(与Write-Through互斥)是指向存储设备内写数据命中时,CPU将数据写入Cache,并不立马向存储设备写入数据,如下图所示:数据先写入到Cache内(①),在Cache内标记该Cache Line为dirty,即表示该Cache Line内容与Memory内容不符;Cache内数据写入Memory(②),则在Cache Line被替换或手动执行write-back操作或flush操作时(把dirty的数据写入Memory)才执行。
未命中时,则写入Memory。是否写入Cache 由xxx-Allocate决定。
Write-Through
Write-Through(与Write-Back互斥)是指向存储设备内写数据时,无论命中与否,CPU都将数据写入Memory。
命中时,数据同时写入Cache 与Memory;
未命中时,数据写入Memory,是否写入Cache 由xxx-Allocate决定。
xxx-Allocate
xxx-Allocate则用于控制读/写未命中Cache时,是否要在Cache内申请Cache Line用于缓存读/写的数据。例如:
Read-Allocate代表读未命中时,CPU不只从Memory将数据读入,还将数据在Cache放了一份,那么下次再读的时候就不用去Memory读了;
Write-Allocate代表写未命中时,会在Cache内分配Cache Line储存写入的数据,那么下次读的时候就可以从Cache读了;具体是否写入Memory取决于使用的是Write-Back还是Write-Through。
Non-Allocate和 Read-and-Write-Allocate就不再进行解释了。
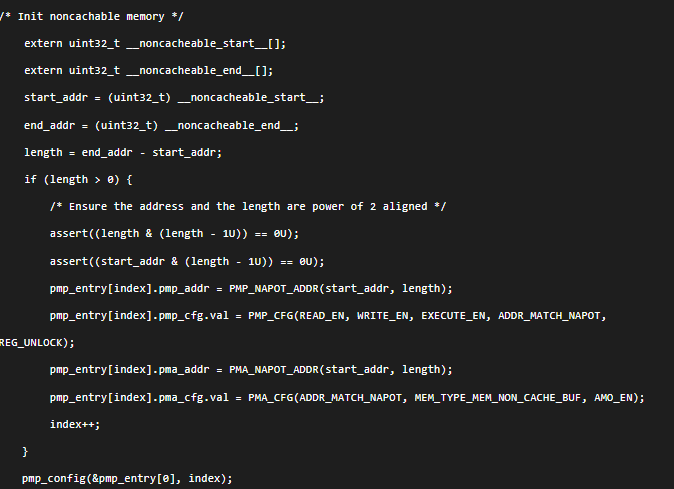
以上代码设置了__noncacheable_start__至__noncacheable_end__地址范围内的存储区域PMA属性为noncacheable,bufferable。
通过以上解释,相信开发者可以看懂UM手册内的相关描述了,以HPM6200系列为例,User Manual v2.0 2.8章节的内容对PMA有详细描述。
二、HPM L1-Cache相关函数
HPM系列芯片L1-Cache分为 iCache与 dCache,指令缓存与数据缓存。开发者们经常遇到的问题是开启dCache导致的CPU拿到的数据与Memory内数据不一致(Cache内的数据与Memory不一致时,读取命中Cache会发生这样的结果)。因此,此处主要介绍 dCache相关函数。
打开hpm_l1c_drv.h文件即可看到先楫提供的Cache相关的函数,部分如下:
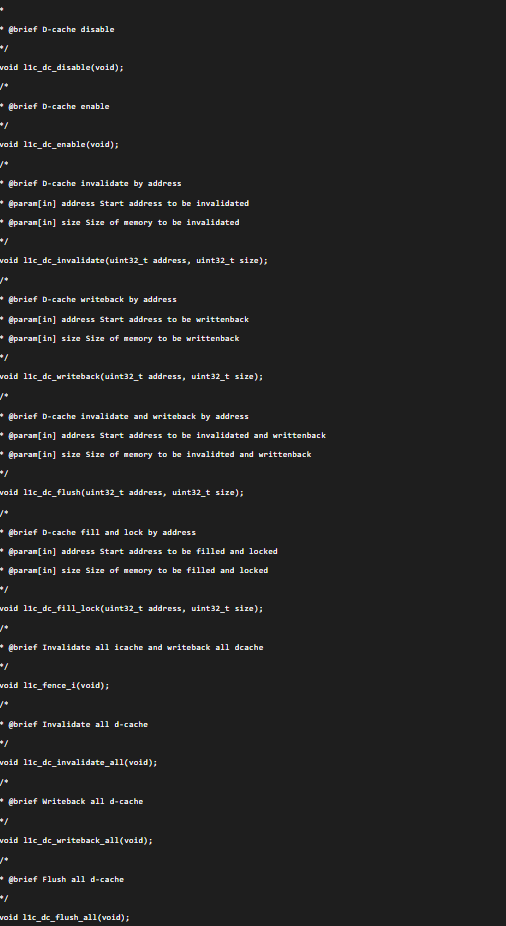
l1c_dc_disable:关闭dCache。此函数特别有用,在debug时如果怀疑是Cache导致的问题,在main函数开始关闭dCache再次运行即可排查是否是Cache导致的问题。注意,如果是用户程序运行过程中关闭dCache,需要在关闭前将执行l1c_dc_writeback_all,保证Cache数据写入Memory。
l1c_dc_enable:开启dCache。
l1c_dc_invalidate:将某地址范围内的Cache Line失效掉。无论某地址在Cache内是否命中,CPU会从Memory内拿数据。
l1c_dc_writeback:将Cache内数据写入某Memory地址。如果该地址在Cache内,则将该Cache Line写入Memory,并清除dirty标志。
l1c_dc_flush:该函数等于 l1c_dc_writeback + l1c_dc_invalidate,把数据写入到Memory并标记为invalidate,表示下次从Memory拿数据时不走Cache。
l1c_fence_i:将dCache内的数据全部writeback,将iCache内所有Cache Line invalidate。一般关闭Cache前会手动调用此函数。
l1c_dc_invalidate_all、l1c_dc_writeback_all、l1c_dc_flush_all:代表操作整个Cache中的Cache Line,具体含义不再赘述。
三、经验分享
l1c_dc_writeback:一般非CPU的总线host,如DMA访问某Memory地址前,通过l1c_dc_writeback将Cache内的数据写到Memory,保证DMA拿到的数据与CPU看到的数据是一致的。
例如I2C_DMA例程:
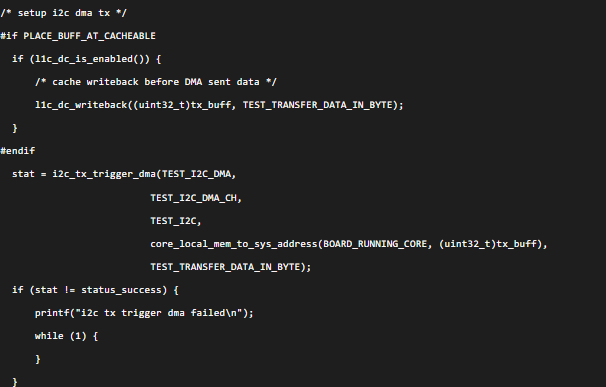
在DMA将tx_buff数据搬到I2C的发送寄存器之前,进行了writeback。
l1c_dc_invalidate:一般CPU在读取Memory数据时,如果该数据被其它总线host如DMA操作过(一般是DMA搬了某些数据过去),为了能读到Memory中的数据而不是Cache中的数据,要在读取之前对Cache Line进行invalidate处理(多数开发者遇到的都是这个问题)。
例如I2C_DMA例程:
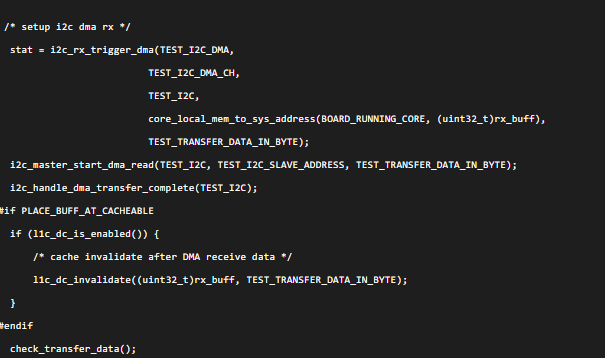
在进行check_transfer_data之前,先对数据进行了l1c_dc_invalidate处理。
l1c_fence_i:一般在CPU关闭Cache之前,或程序跳转之前(一般二级boot选择好要执行的固件进行跳转),为了保证所有dirty的Cache Line写入到Memory中,会进行l1c_dc_writeback_all,然后等 l1c_dc_writeback_all执行完毕后再跳转。
例如tinyuf2例程:
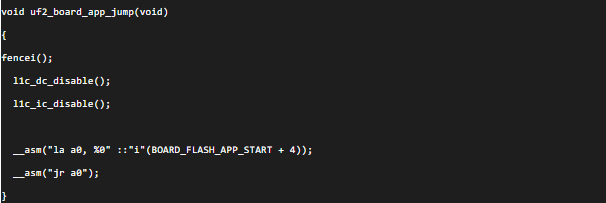
uf2_board_app_jump函数在跳转前,执行了fencei,本质上就是l1c_fence_i。
另外,在执行writeback操作期间中断不可用,对实时性要求高的场景应进行合理规划l1c_dc_writeback_all的使用。
四、文末小结
Cache能大幅提高程序运行性能,但用不好Cache也会给开发者带来各种“奇奇怪怪”的问题现象。在阅读本文后,希望开发者对先楫的 L1-Cache有更深入的理解,使用先楫半导体高性能 MCU系列产品开发项目时,能更加得心应手。
