


















二、问题点
(一) SPI FIFO poll阻塞发送无法发挥SPI理论速度性能
使用spi poll阻塞的时候,虽然能实现数据的完整传输,但是传输的时间并不能达到理想传输速度,比如SPI四线模式下,30M的SPI SCLK时钟,理论可以达到15MB/S速度。但实际测量当中并未达到该性能。从逻辑分析仪看到,发送flas一页数据,也就是256字节,从开始传输到结束传输的时间需要37.034us,合计为6.91MB/S,与理论速度相差了2到3倍的距离。
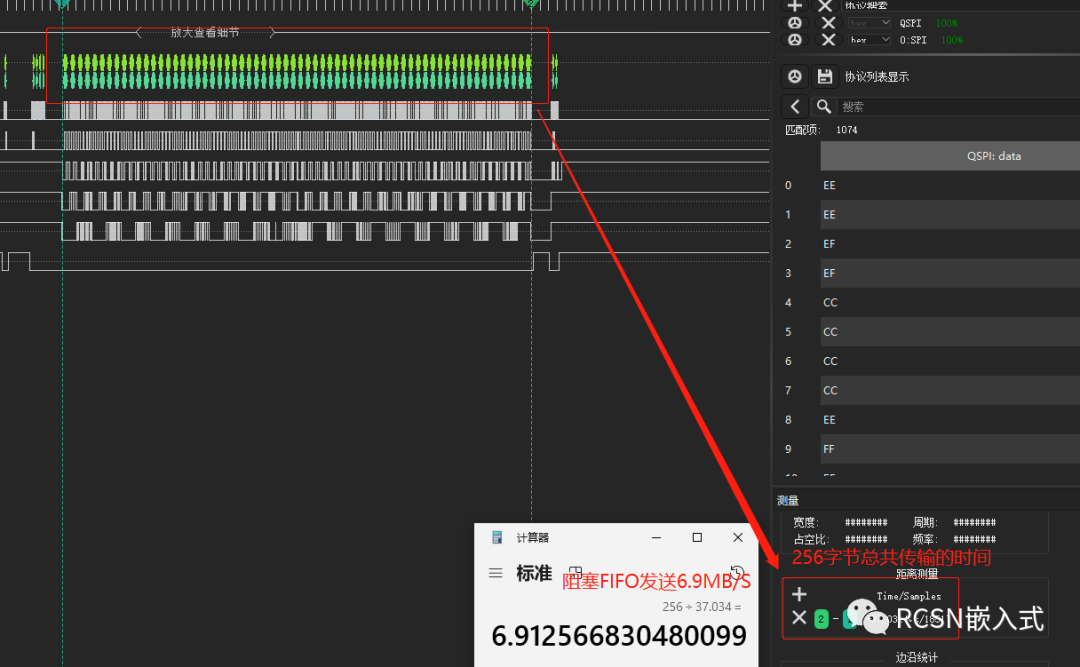
从波形上看,导致这个速度达不到原因就在于,每个字节之间存在了一定的间隔时间,这些间隔的累积导致传输时间变长,导致总的时间变长,进而速度远远跟不上。
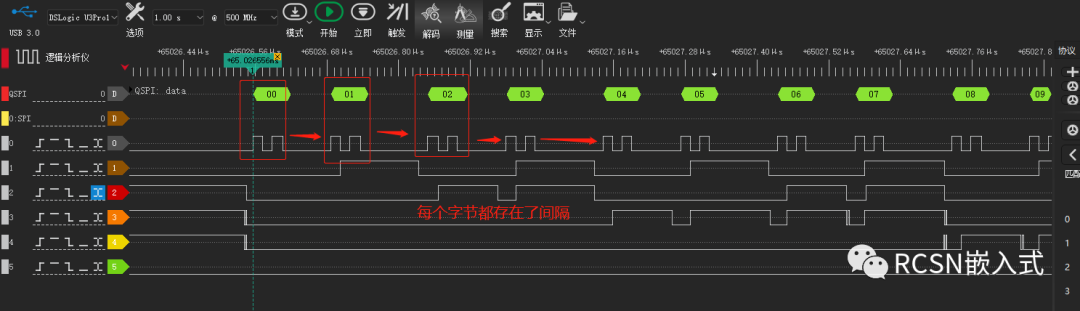
(二)使用了DMA仍然有SPI SCLK时钟不连续问题
从(一)的问题可以看出,要想达到理论速度,必须消除每个字节的SCLK间隔,缩短传输时间。这时候需要DMA来加持速度性能,但实际上,在使用了相关配置之后,速度虽然有些提升,但还是存在些许间隔产生。
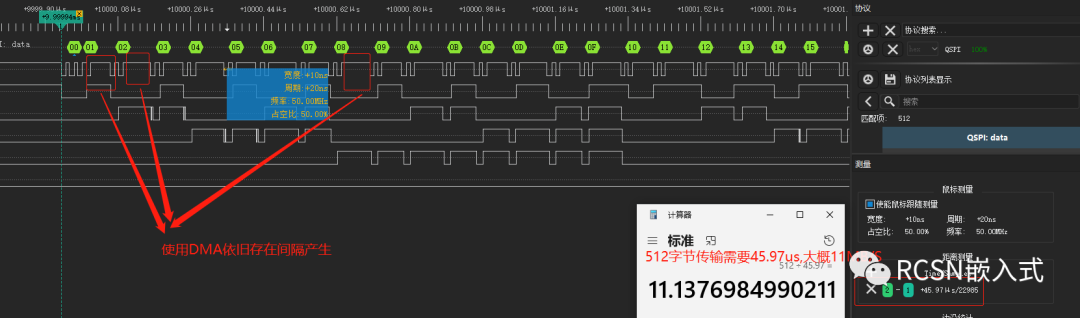
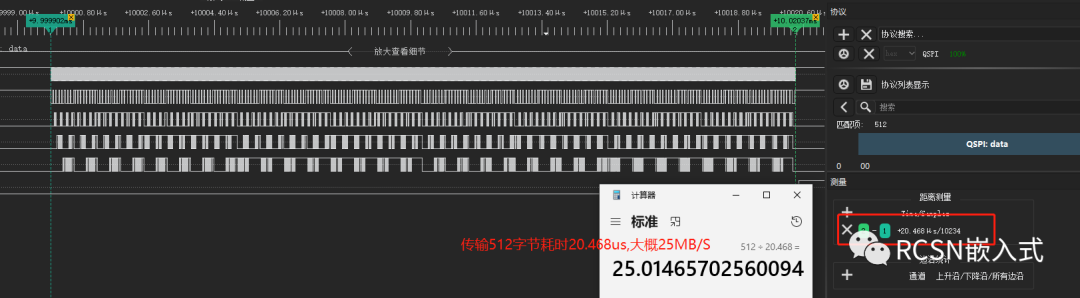
在这里的例子验证条件是:SPI SCLK时钟频率为50M,主机发送512字节。理论传输速度可以25MB/S.从逻辑分析仪可看到,间隔有所缩短,但依然存在字节间隔。512字节传输需要45.97us,合计为11.173MB/S。距离25MB/S也有两倍的差距。
三、解决问题
在二问题的所有描述当中,速度达不到理想性能,归根到底是字节之间产生间隔累积形成。
所以我们的问题解决点是:再配合DMA,进行其他优化。达到理想速度性能。
(一) 使用AHB SRAM(内存32KB空间)作为数据交互RAM。
在HPM6000系列中,AHB/APB外设总线连接了一个内存为32KB空间的AHB SRAM,与之同时连接的也有DMA控制器之一HDMA。
从官方文档可知,AHB SRAM和HDMA以及SPI外设同样位于AHB/APB外设总线中,AHB SRAM是专门给HDMA进行低延时访问的内存,也是SPI进行DMA低延时传输保证。
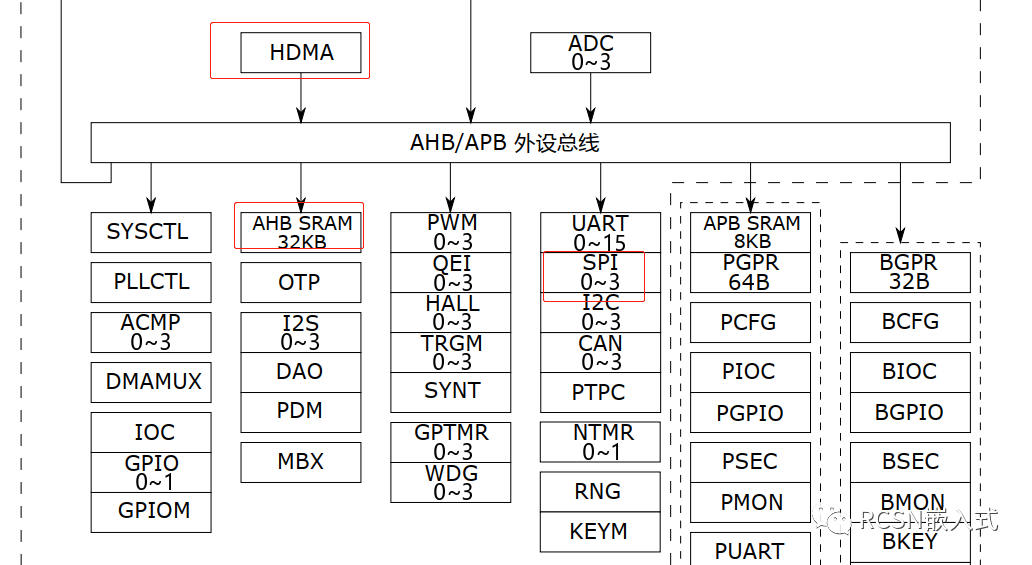
在上面的DMA搬运中,待发送的数据放在AXI SRAM中。那么把这发送的数据放在AHB SRAM,看下会不会有所提升。

从以下逻辑分析仪结果看出,传输512字节,相比放在AXI_SRAM中,在AHB_SRAM只需要22.97us,缩短了23us, 合计22MB/S,提高了两倍速度性能。当仍与25MB/S理想速度有些许差距。
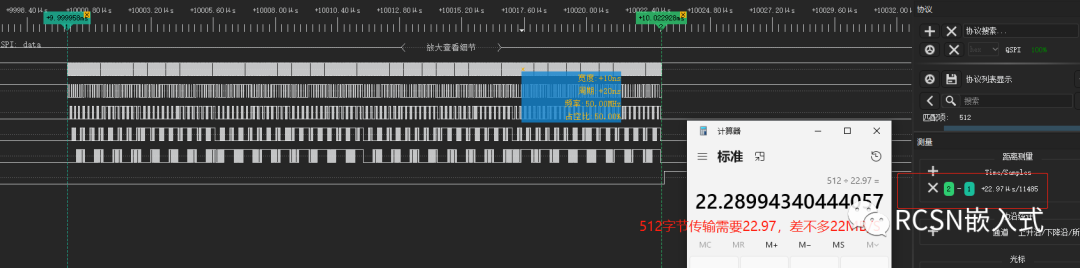
通过放大波形查看,有些字节依然产生间隔,这也是导致速度没达到理想速度的原因。
(二)使用DMA的burst突发传输
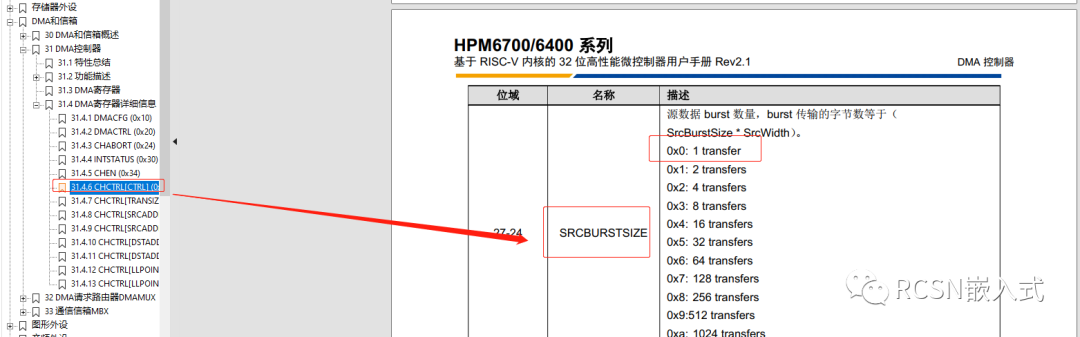
先楫的DMA,对于源地址数据来说,支持突发传输。例如传输位宽为8,设置burst数量为4,那么就是相当一次DMA请求设置了4个节拍,连续传输4个字节。是单次传输的4倍效率。在这里来说,待发送的数据就是源地址数据。
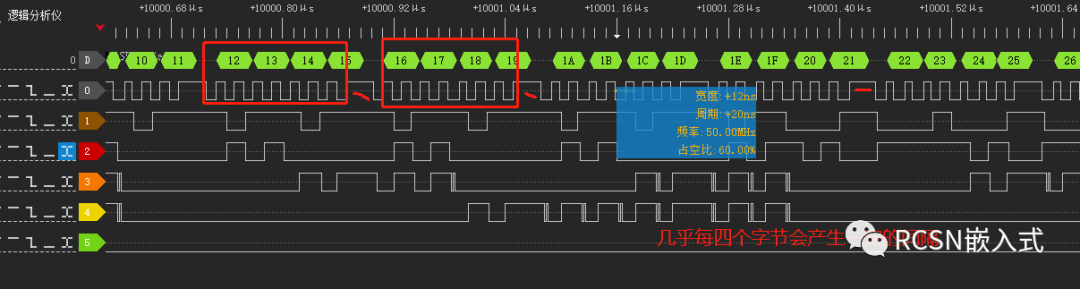
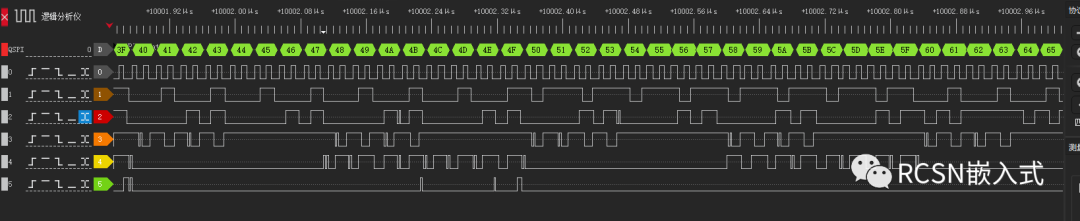
先楫的SPI控制器有四个字的FIFO数据空间,每个FIFO是32位。SPI请求DMA搬运是通过发送FIFO阈值请求。从效率上来看,最好是一次请求中能把FIFO数据全部搬运。从上面的优化流程来看,都设置为了默认,TX FIFO阈值设置为了0,也就是只要TXFIFO有一个为空就请求一次,DMA的源数据burst数量为0,也就是相当设置了1个节拍的突发传输,传输宽度为8位,一次DMA请求就塞给一次FIFO,等待FIFO完全塞满后这时候没法请求,所以会导致一次周期的间隔,当DMA收到请求后连这样能解释上面为何每隔四个字节会产生间隔的原因。
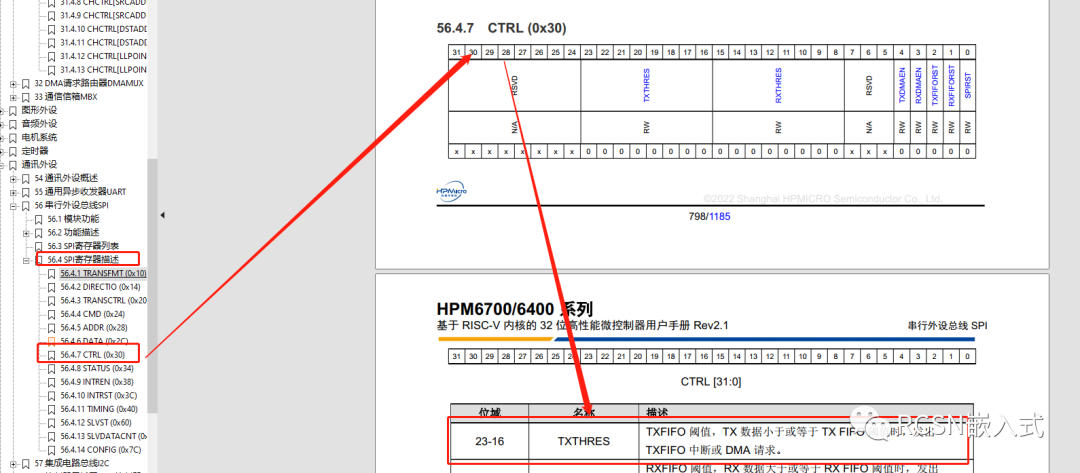
所以这里我们可以SPI的TXFIFO阈值为3,当出现一个空位的时候就请求一次,设置burst数量为2,也就是四个字节,一次请求搬运四个字节。通过逻辑分析仪可看到:
配合(一)的方案,传输512字节,只需要20.468us,合计为25MB/S左右,接近了理想速度性能了。
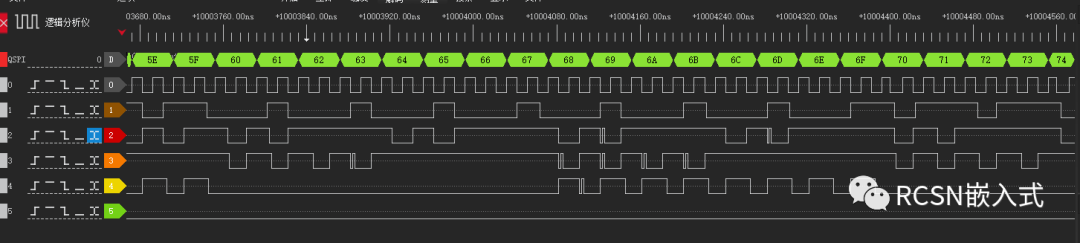
放大波形查看,也能看到SCLK时钟连续了。
(三)压榨性能(使用SPI的字节合并merge功能)
先楫官方手册说明的是SPI时钟可以80M,保守是40M。在四线模式下,SPI时钟SCLK为80M,相比单线来说可以提高四倍性能传输,也就是可以达到40MB/S。
但是在实际操作的时候,分频SPI SCLK频率到66M,又出现了SCLK时钟不连续的情况,导致与理想速度不符合。
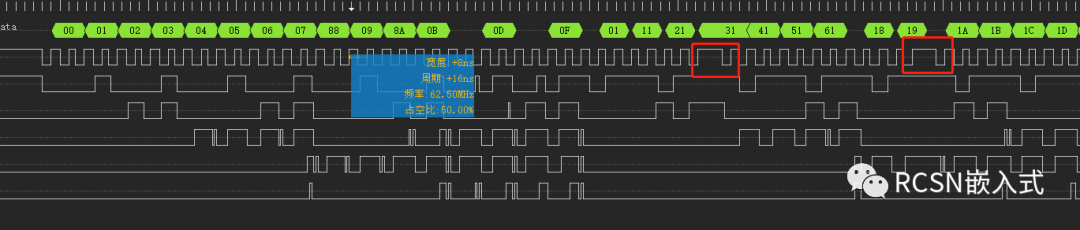
仔细翻下官方手册,可以知道SPI有个寄存器是TRANSFMT,有一个位是DATAMERGE,对于描述如下:
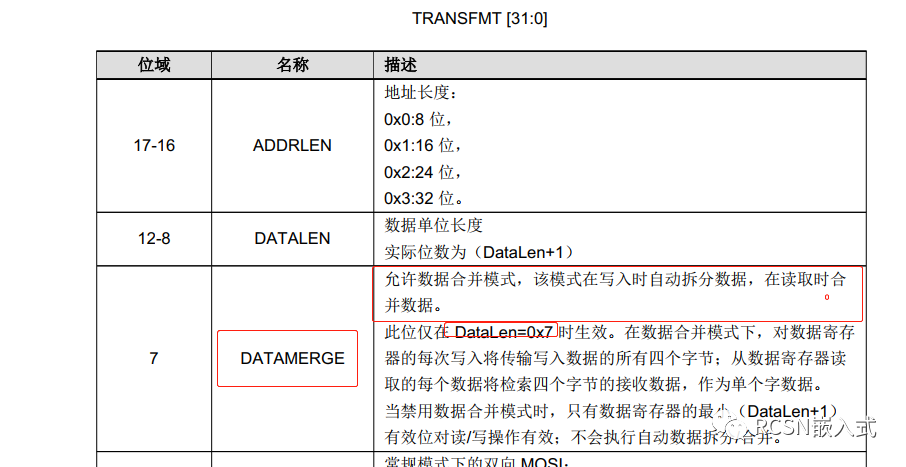
特别说明的是,由于SPI的数据FIFO是32位,这个功能只在数据单位长度为8位的时候有效,而且合并的数据量需要以四的整数倍。如此来说,在配置DMA的时候,传输宽度可以从8位变到32位,传输的带宽也能提高了四倍。那么我们这样配置下,逻辑分析仪结果如下:
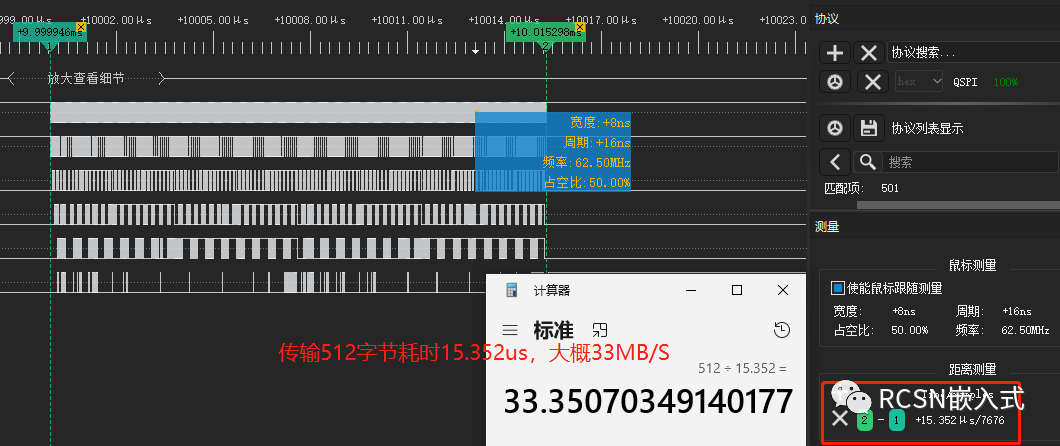
在66M的SPI SCLK时钟下,逻辑分析仪抓到的SCLK能保持连续,并且数据能对得上。512字节耗时15.352us,合计33MB/S左右,与理论速度33MB/S接近。
80M的SPI SCLK频率,传输512字节,耗时12.794us,合计40MB/S左右,也能满足预期40MB/S速度。

SCLK波形也能保持连续。
四、号外(单线SPI总线可以达到120M)
四线模式既然能达到80M,那么楼主想试下80M的单线,也是没问题的,效果如下:

再尝试一把,把SPI SCLK分频到120M,只是稍微有点间隔,但单线SPI也是没问题的。

五、总结
对于先楫这个SPI外设来说,配合DMA,SPI的数据FIFO以及相关SPI配置,能达到手册描述的性能。无论是四线模式还是二线模式还是单线模式,都能到达80M的SPI时钟性能。
对于SCLK不连续的问题在于DMA搬运和SPI传输不同步造成,导致传输间隔中断,特别是SPI频率越来越高的情况下。解决同步问题就不会有SCLK不连续的问题存在。
以上内容来自先楫开发者的原创分享。
我们始终相信开发者共创的力量。先楫社区坚持开源共享、互惠互利,贴近每一个开发者,一步一个脚印,一点一滴积累,为成为更好的我们而不断努力。
心之所向,锐意进取,星辰大海,恣意成长。
MCU生态建设需要您的贡献与支持!欢迎广大爱好者和开发者踊跃投稿,供稿请联系sha.li@hpmicro.com。
